We Stopped Rolling Out Features by Updating Millions of Rows


Over the last two months, Mathspace's feature flag system evaluated 6.6 billion flags, averaging 110 million flag decisions per day. The two request-path lookups needed for those decisions, fetching user attributes and loading the compiled rule config, stayed around 40 ms at the 99.5th percentile.
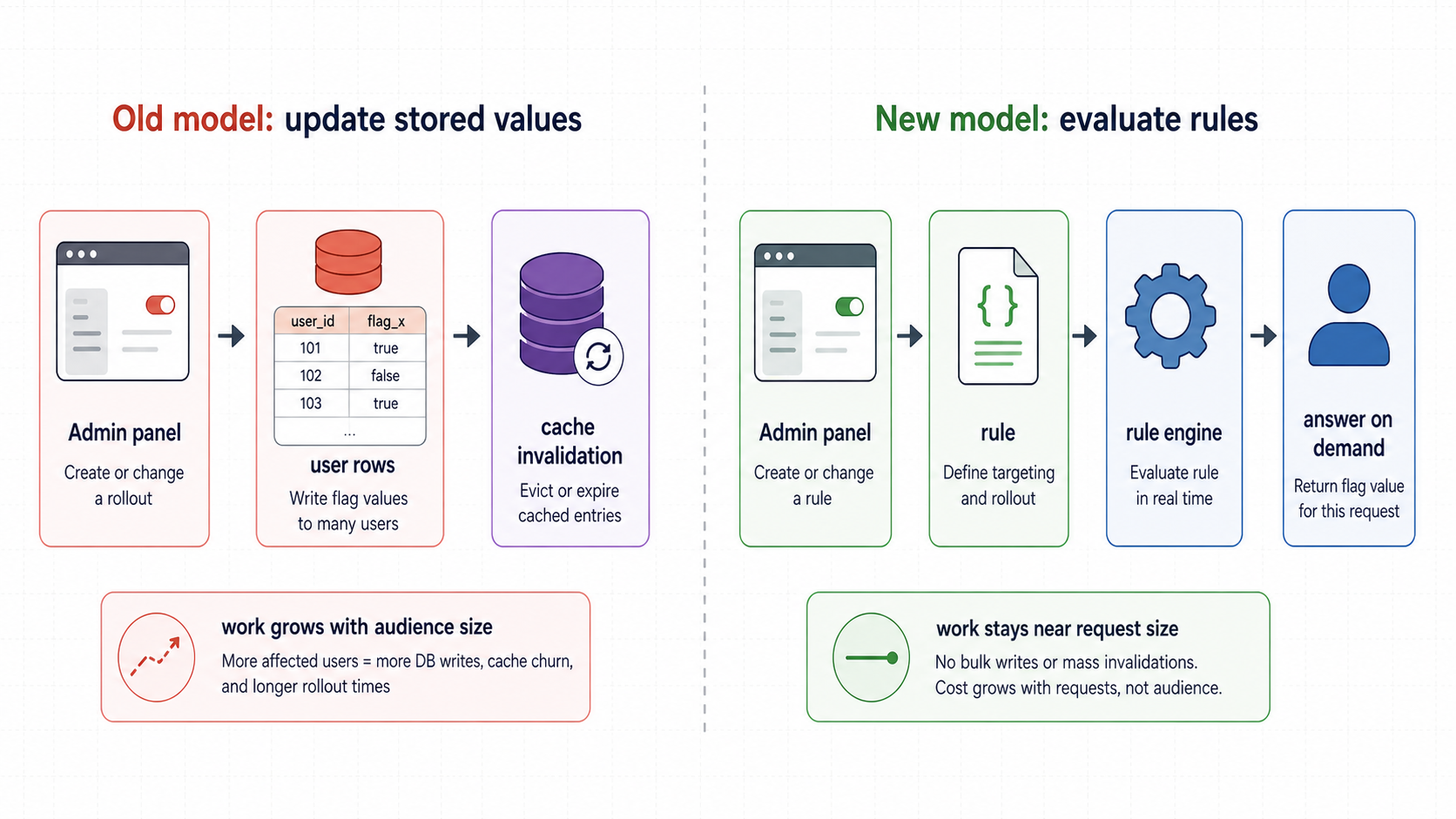
Those numbers matter because our old system had the wrong mechanical model. A rollout was not a rule that the app evaluated when a user arrived. It was a stored answer written onto users, schools, and districts ahead of time. Changing a broad rollout meant changing a broad slice of the database. If the change affected half the user base, the work scaled with half the user base.
Feature Flags V2 changed the unit of work. Instead of writing new answers to many rows, we store a small rule document and answer the question on demand: given this user and these rules, what should they see?
The Old Shape
Mathspace is an online maths learning platform used by schools, teachers, and students. Most of the product still runs through a large Django application, or monolith: one main codebase and runtime serving many product areas.
The first feature flag system grew up inside that monolith and did useful work for a long time. It could store defaults, override a flag for a user, a school, or a district, and expose those values to backend and frontend code.
The trouble was how rollout changes happened.
FFv1 treated feature flags as stored values. If we wanted to enable a feature for a cohort, the system selected the affected users and wrote flag overrides to their records. Some cohorts were predefined buckets based on user ID. Random rollout existed too, but the implementation still selected user IDs and then updated rows in batches.
That has two awkward consequences:
- Rollout work grows with the number of affected users, not the number of rules.
- Changing the rollout is a write operation against core product data.
During quiet periods, that may be tolerable. During school-day traffic, a broad rollout could sit in background jobs for a long time. A half-user-base change could mean hours of database writes and cache churn.
The Cache Was Part of the Problem
FFv1 also carried history from several caching strategies. One of them was cacheops, a Django library that caches ORM query results in Redis and tries to invalidate related cached data when writes happen.
Redis is a fast in-memory data store. It is excellent when the access pattern is controlled. It becomes less excellent when one product operation can trigger a very large, hard-to-predict invalidation pattern.
The git history around FFv1 reads like a system pushing against that boundary with constant fixes to reduce or optimize caching issues over time.
The important point is not that cacheops was bad in every context (albeit it is a very easy tool to misuse). It was the wrong class of problem for implicit cache invalidation. Feature flag rollout needs predictable cost. A broad rollout should not create a broad write storm and then ask Redis to absorb the blast radius.
The New Shape
FFv2 uses FeaFea, our small open-source rule engine. It takes facts about a target and a set of rules, then returns a decision.
In our case, the target is usually a user. The facts are attributes such as:
- whether the user is a teacher or student
- which school, class, or district they belong to
- the country or region of the school
- explicit user, school, or district overrides
The rule document says things like:
For teachers in this country, enable the new report.
For 20% of students in this rollout group, show the new workbook flow.
For this one school, force the old behavior until support is ready.
The exact syntax is more precise than that, but the model is the same. Rules are configuration. Product code still asks a normal question:
if user.feature_flags_v2.enableNewExperience:
...
Behind that line, FFv2 retrieves the user's attributes, asks FeaFea to evaluate the compiled rule set, and returns a typed flag value.
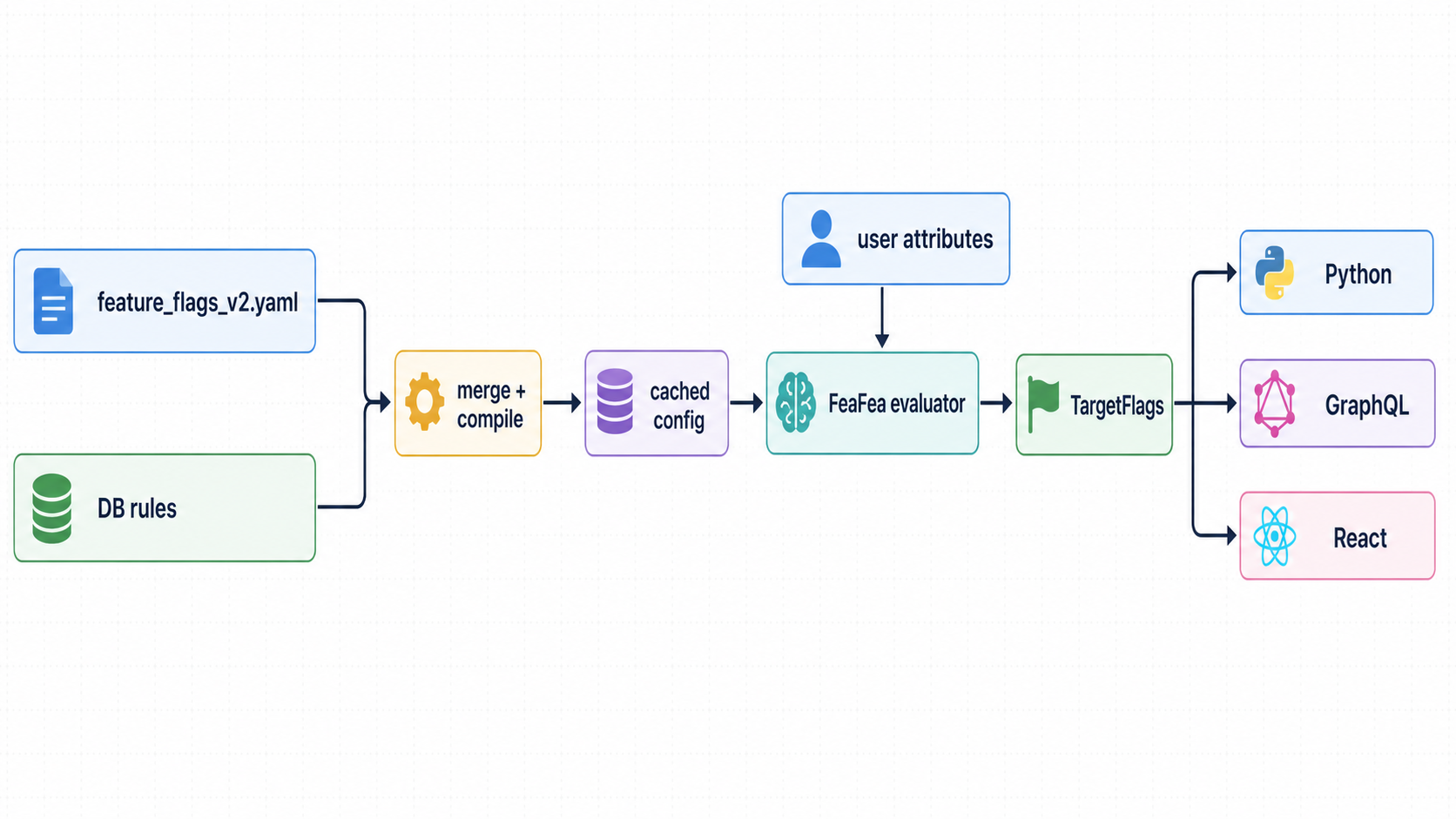
There are still stored values, but they are stored in the right places:
- flag definitions live in a YAML file in the repository
- live rollout rules live in a small database table
- compiled rule config is cached
- user, school, and district attributes are cached for 36 hours
- generated Python and GraphQL types keep application code from passing raw strings around
Changing a rollout now means changing a rule document, compiling it, and letting future requests evaluate against it. The work is proportional to the size of the rule change and the requests that actually happen, not to the number of users who might eventually match.
Why FeaFea Can Sit in the Hot Path
Putting rule evaluation in the request path only works if the engine does very little at request time. FeaFea is built around that constraint.
When config changes, FeaFea validates and compiles it into an immutable CompiledConfig. Filter strings are parsed ahead of time, named filters are inlined to avoid extra calls, set literals are hoisted out of the expression, and rule order is fixed by priority and name. Compilation also builds per-flag rule lists, so evaluating one flag does not scan unrelated rules.
At request time, evaluation is intentionally small: validate the attributes shape, add a timestamp, walk the compiled rules for the requested flag, and return the first matching variant or the default. Percentage rollout uses a stable hash, so cohort membership can be derived without storing membership rows. The expensive work is pushed to config update time; the hot path mostly runs precompiled Python callables over a dictionary of attributes.
Stable Splits Without Stored Cohorts
Percentage rollout still needs stability. If a teacher is in the 20% group today, they should not jump out tomorrow just because we changed the rollout from 20% to 50%.
FFv2 handles that with deterministic split rules. A rule can ask whether a user falls into a stable bucket for a named rollout group. Related flags can use the same split group so they move together.
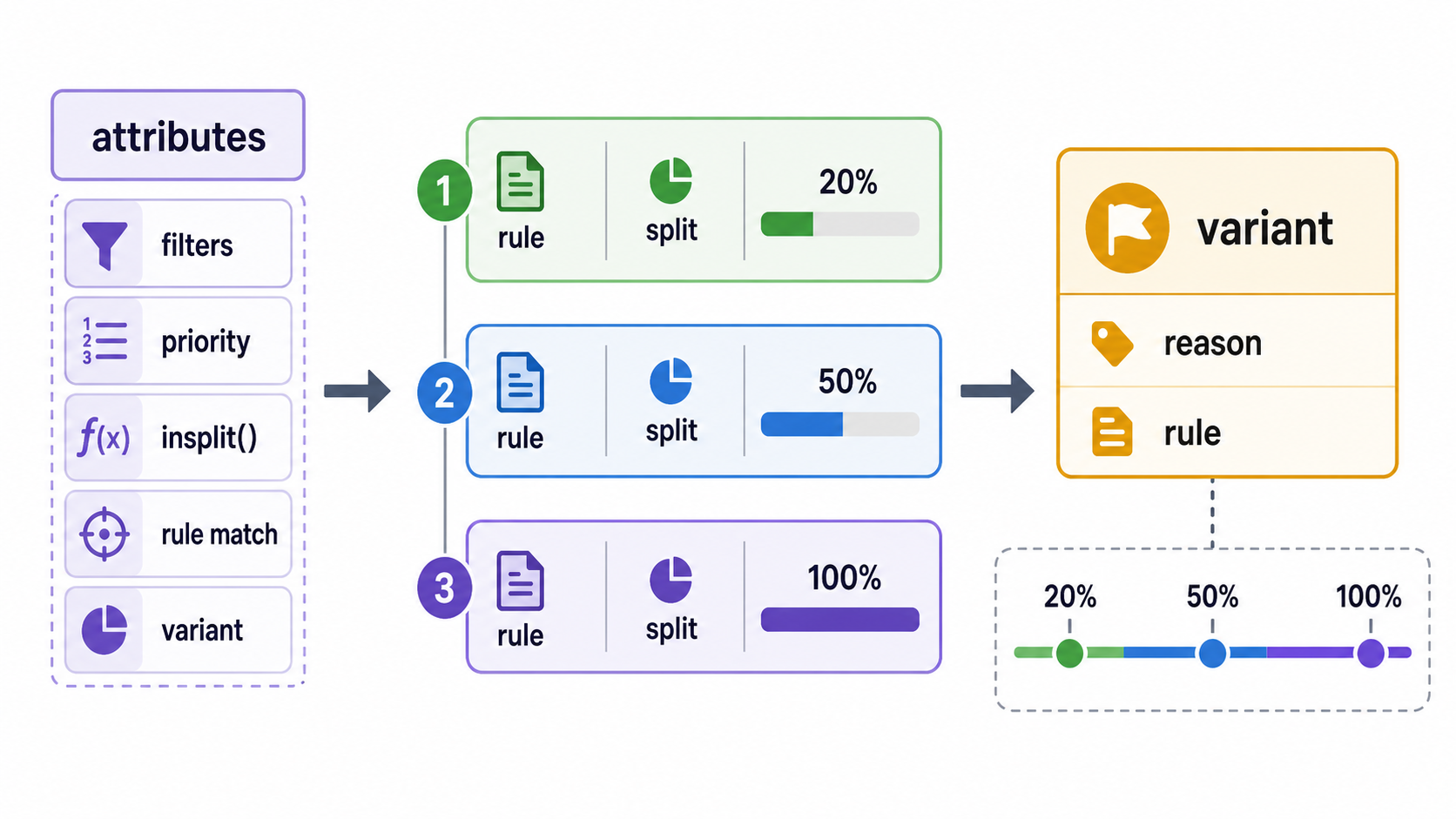
That is the difference between storing membership and deriving membership. FFv1 often materialized the answer: this user has this flag value. FFv2 stores the recipe: this rule applies to this range of the stable split.
The recipe is easier to change. Expanding from 20% to 50% edits the rule. It does not require writing a new flag override onto every newly included user.
Finally, a split can target any attribute, not just a blessed user one.
Safety Moved to the Workflow
Moving from stored answers to evaluated rules creates a new risk: a bad rule can affect many users immediately.
So FFv2 tries to make the editing path boring and explicit. The admin screen can evaluate unsaved rules against a specific user before saving. That check returns not only the final value, but the reason and matching rule. A release owner can ask, "what would this teacher get?" and see the decision before the rule becomes active.
The save path compiles the candidate config before accepting it. If merge or compile fails, the save is rejected and the current config stays in place. During deployments, a time lock can block rule edits so config changes do not race code changes.
This is not perfect. A long-running editor can still save a stale version of a rule document after another edit has happened. The current system uses locking around writes, but optimistic version checks remain a known gap. That is the kind of imperfection worth naming because it is exactly where rollout systems need discipline.
We also stated an important rule:
The Migration Was Mostly Deletion
The code history has a nice arc. At first, FFv1 gained helpers: typed flags, GraphQL exposure, cohort selection, signup assignment, admin actions, random experiments, cleanup tasks, async bulk jobs. Those were all reasonable responses to real product needs.
But each helper was trying to make the stored-answer model more flexible. Eventually the model itself was the constraint.
Once FFv2 was available, the cleanup work became simpler and more revealing:
- migrate feature flags from FFv1 to FFv2
- deprecate FFv1 flags with no users or code usage
- remove DB-backed FFv1 definitions
- remove FFv1 migration tooling
- remove FFv1 bulk cohort and random update tasks
- remove cacheops usage from the feature-flag path
- delete obsolete signup and updatable-flag models
That is usually a good sign. A replacement is healthy when it lets you delete special cases rather than preserve them behind adapters forever.
The Lesson
The main lesson was not "use a rule engine." It was "choose the right time to answer the question." This stems from approaching the problem from first principles and not merely "improving" on the existing situation.
FFv1 answered early and stored the answer. That made reads simple, but it made rollout changes expensive and operationally noisy.
FFv2 answers at the moment the product needs the answer. That makes each request do a small amount of work, so the request path needs caching and measurement. But it turns rollout changes back into configuration changes, which is what feature flags were supposed to be.
There is a broader engineering principle here:
That is the engineering culture we want to keep building: curious about old assumptions, strict about operational cost, and willing to delete a familiar system when the model is wrong.